Back
Katherine Peng
2026
Choosing the right agentic workflow for our AI product MVP
Context
We’re building an agentic workflow to support medical/market access consultancy work: rapid synthesis, high defensibility, and compliance-safe outputs.
The core reality: in this domain, a “pretty answer” is worthless if it can’t survive review. Trust isn’t a nice-to-have — it’s the deliverable.
What success looks like
I framed the decision around five non-negotiables:
Defensibility
Every meaningful claim needs a traceable citation + supporting snippet.
Governance
Clear handoff points for human review and approval.
Predictability
No runaway loops, stable cost/latency, repeatable outcomes.
Speed-to-draft
Faster first draft without creating rework downstream.
Scalability
Works across teams, regions, and deliverable types without constant prompt babysitting.
Patterns evaluated and how they perform here
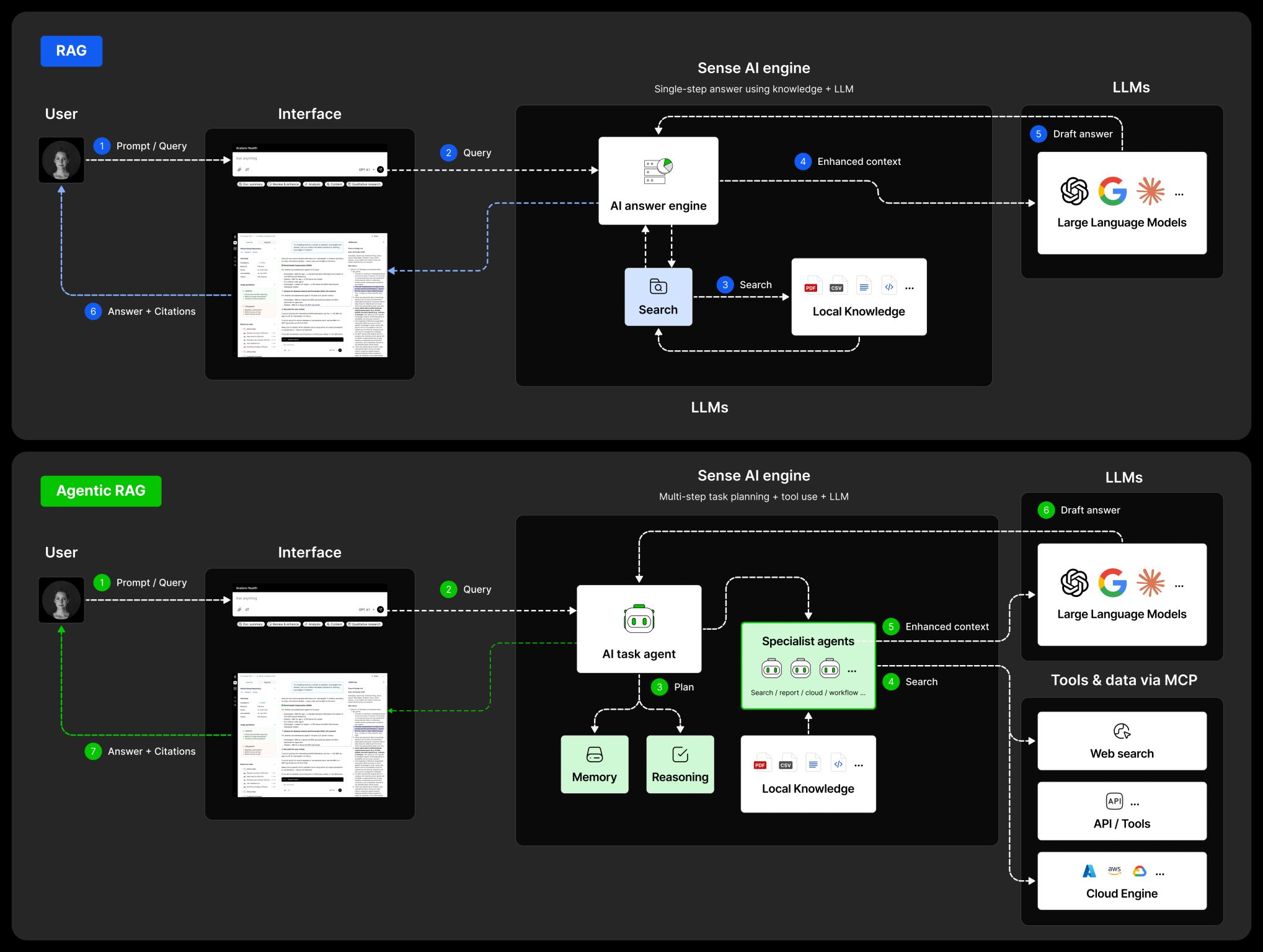
1) Reflection (self-critique and revise)
Where it shines: polishing, clarity, tightening logic, catching missing caveats.
Where it fails: it can “improve” unsupported statements — it doesn’t magically create evidence.
Verdict: essential as a quality gate, but dangerous as the primary workflow.
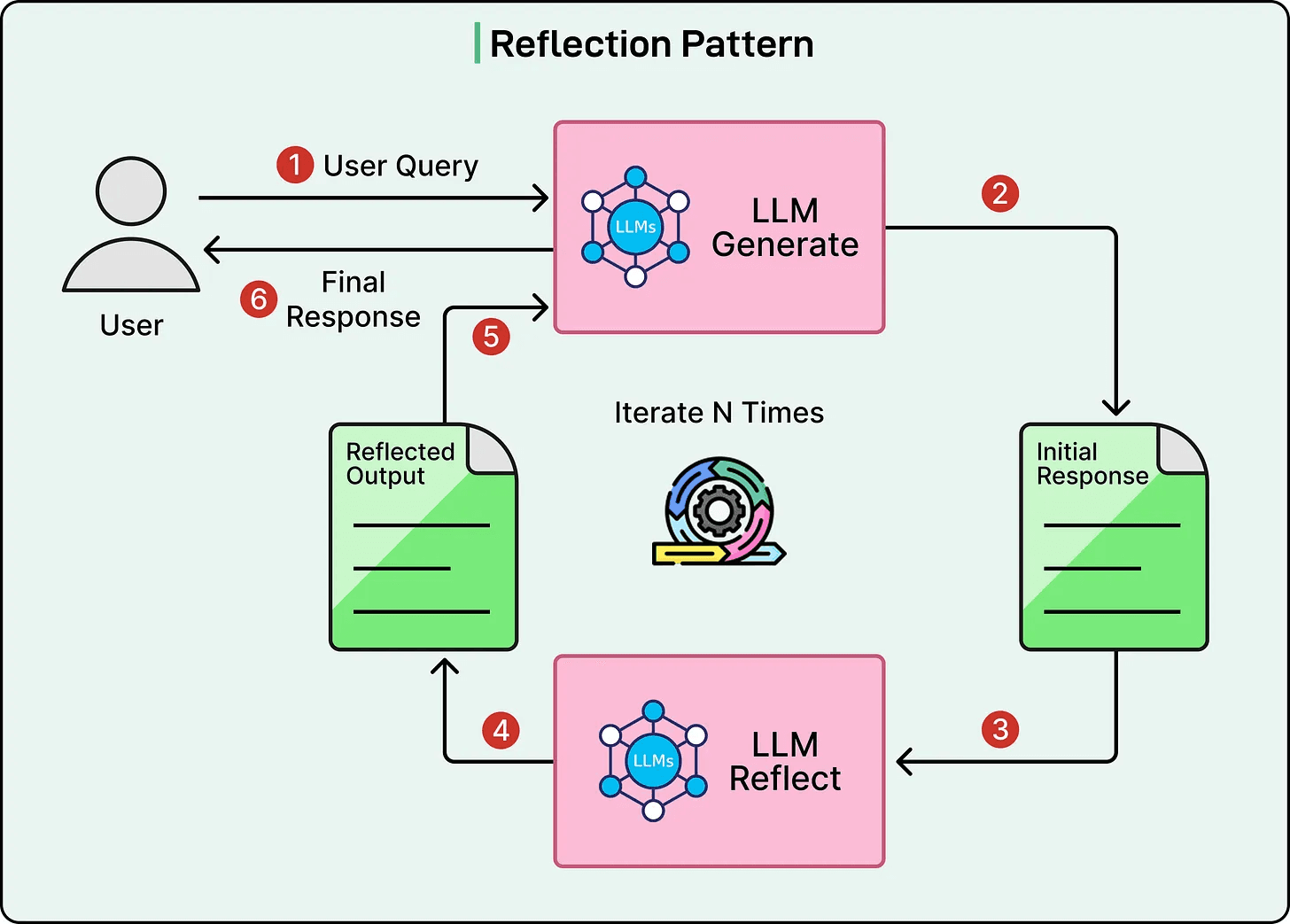
2) Tool Use (agent retrieves from sources/APIs)
Where it shines: evidence-first outputs, citations, provenance — the core of trust.
Where it fails: if tools aren’t constrained, it becomes “random internet research” with a suit on.
Verdict: must-have, but only with approved sources + guardrails.
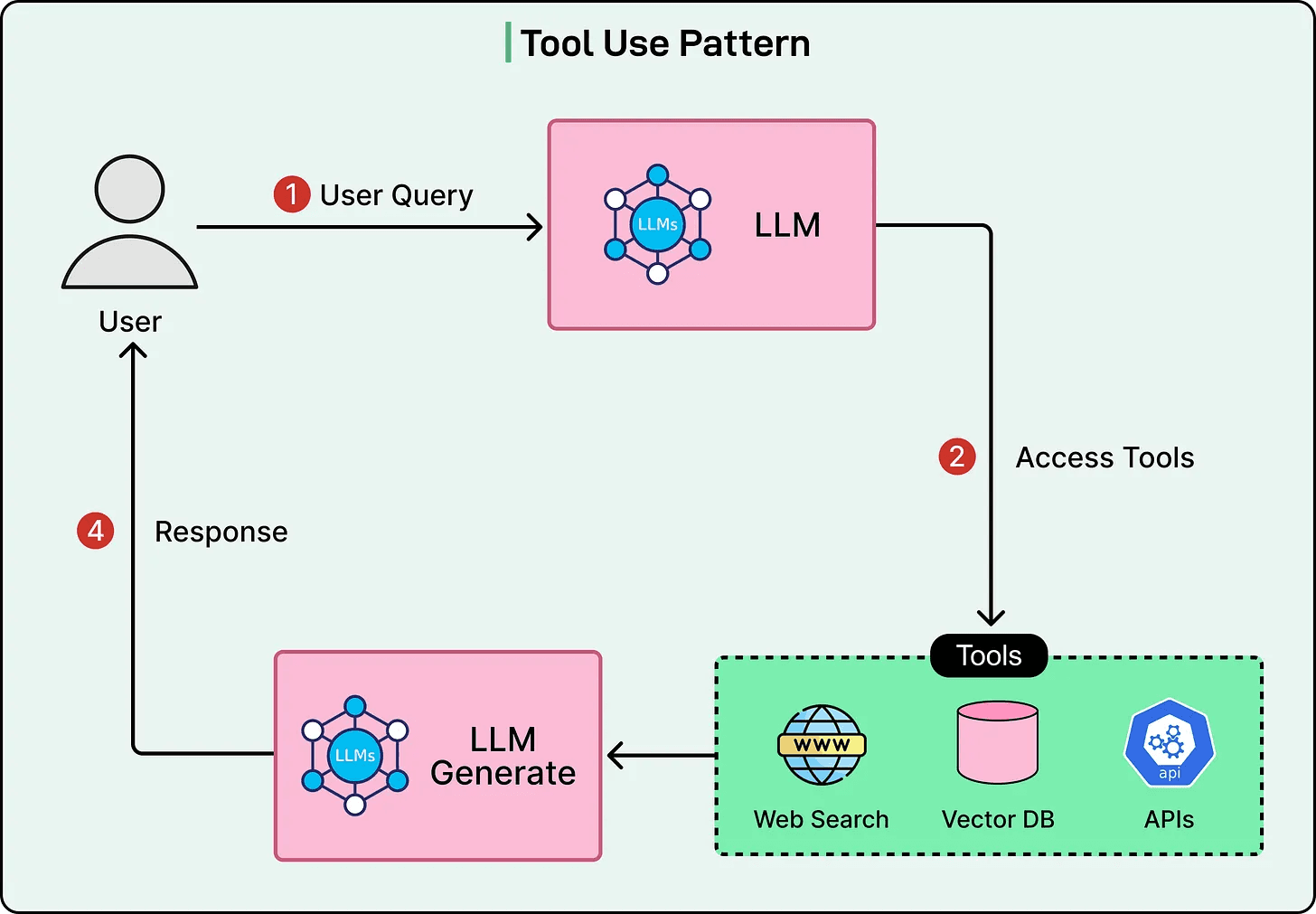
3) ReAct (reason → act → observe → repeat)
Where it shines: exploratory discovery, figuring out unknown paths.
Where it fails: can wander, over-call tools, and produce inconsistent outputs (bad for compliance).
Verdict: useful for exploration mode, not for production-grade deliverables without strict gating.
4) Planning (plan phases, then execute)
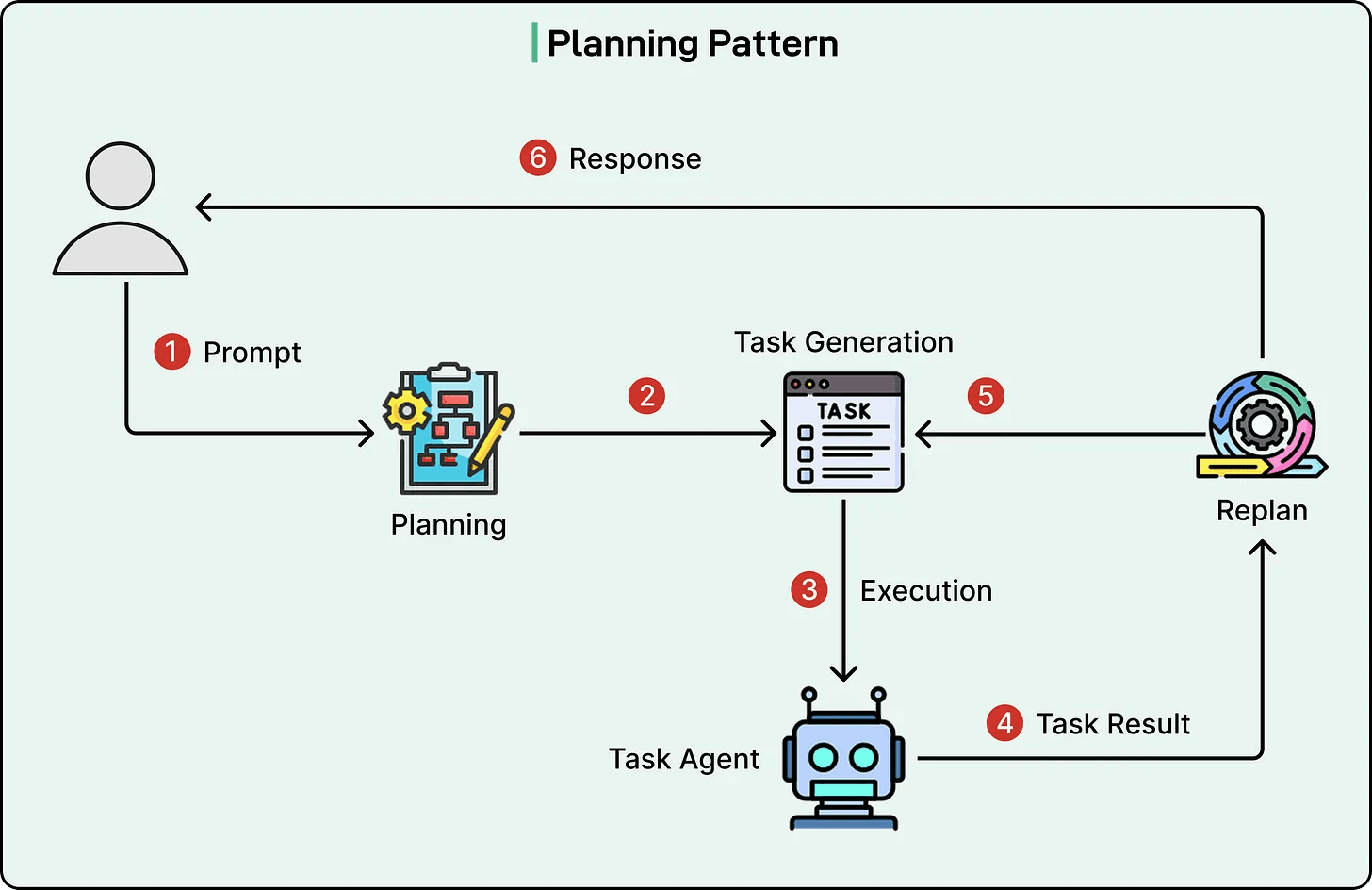
Where it shines: mirrors consultancy delivery: scope → evidence → synthesis → review. Predictable.
Where it fails: adds overhead for simple tasks; can be rigid if over-designed.
Verdict: best “spine” for regulated consultancy workflows.
5) Multi-Agent (specialists + coordinator)
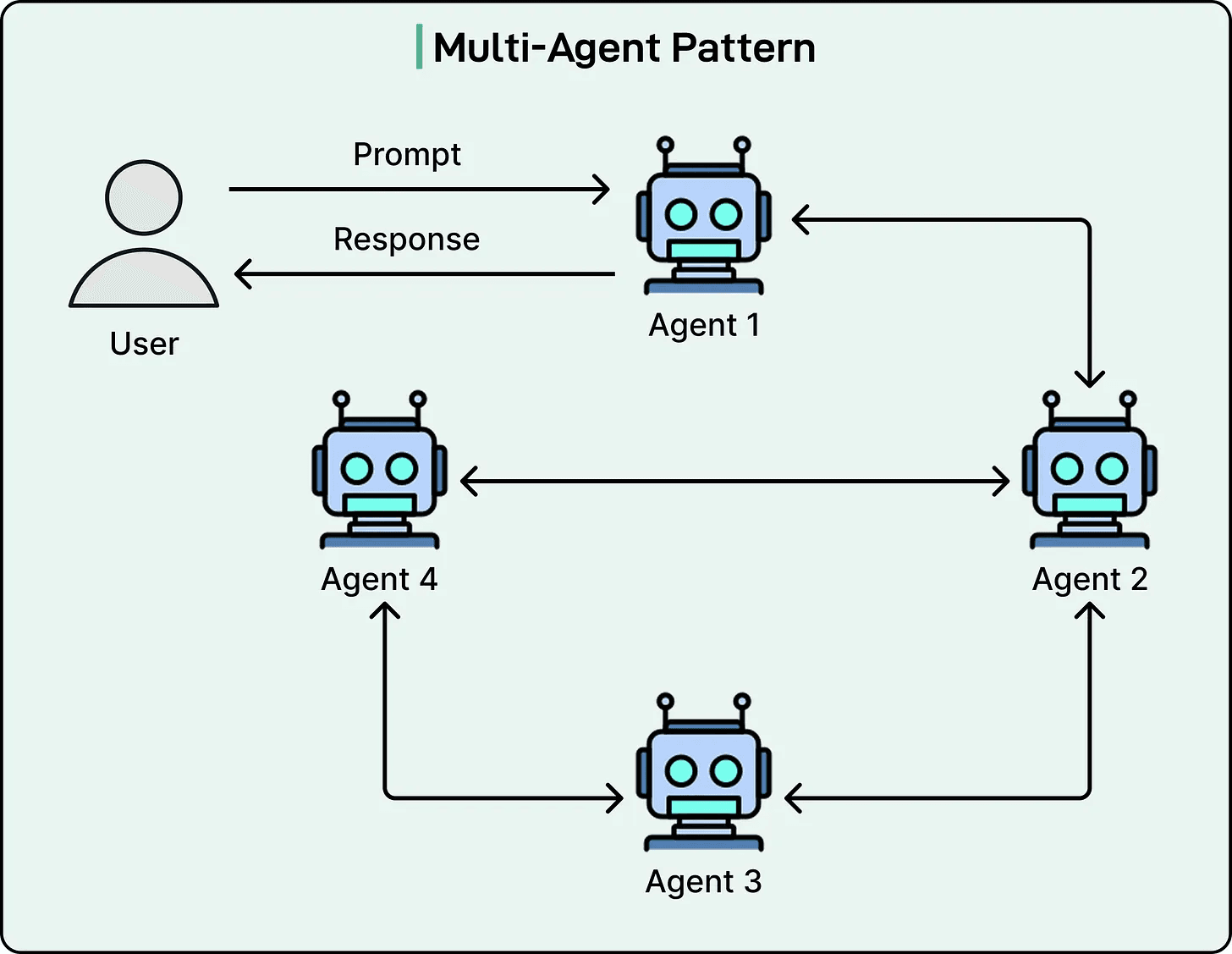
Where it shines: separates concerns (retrieval vs writing vs review). Improves reliability and reduces leakage between steps.
Where it fails: coordination overhead; easy to over-engineer.
Verdict: use lightly, only where separation increases trust and auditability.
Recommended workflow: an evidence-first agentic system designed for regulated consultancy
After evaluating multiple agentic patterns (Reflection, Tool Use, ReAct, Planning, Multi-Agent), I intentionally did not choose a single pattern in isolation.
For Sense AI's medical consultancy context, the correct solution is a composed workflow that balances speed, trust, and governance.
After comparing the main agentic patterns (Reflection, Tool Use, ReAct, Planning, Multi-Agent), I’m recommending a composed workflow rather than betting on a single pattern:
Planning + Tool Use + Reflection, with light role separation for retrieval, drafting, and review.
This combination is the best fit for medical consultancy because it delivers speed without sacrificing defensibility or governance.
Why this workflow fits
In this domain, the “failure mode” isn’t small inaccuracies — it’s unsupported claims reaching clients, prolonged review cycles, and loss of trust. So the workflow needs to be structured and auditable by default.
Planning provides a predictable delivery path that mirrors how consultants already work: scope → evidence → synthesis → review → sign-off. It reduces backtracking and makes the process repeatable across teams and deliverable types.
Tool Use makes evidence first-class. Instead of generating a narrative first and bolting citations on later, the workflow produces an Evidence Pack upfront and drafts only from approved sources. This is the single biggest reliability upgrade.
Reflection is used as a defensibility gate, not an open-ended “self-improve” loop. It checks citation coverage, contradictions, and compliance-safe language before anything reaches human review.
What I intentionally did not choose (and why)
I did not recommend full autonomy or ReAct as the default execution mode. Those patterns are useful for exploration, but they introduce unpredictable tool calls, inconsistent outputs, and higher compliance risk.
I also avoided a heavy multi-agent “swarm” for MVP. It adds coordination overhead and slows delivery. Instead, I recommend minimal separation of responsibilities where it reduces risk: retrieval, drafting, and review remain distinct steps even if orchestration is simple.
Recommended MVP flow
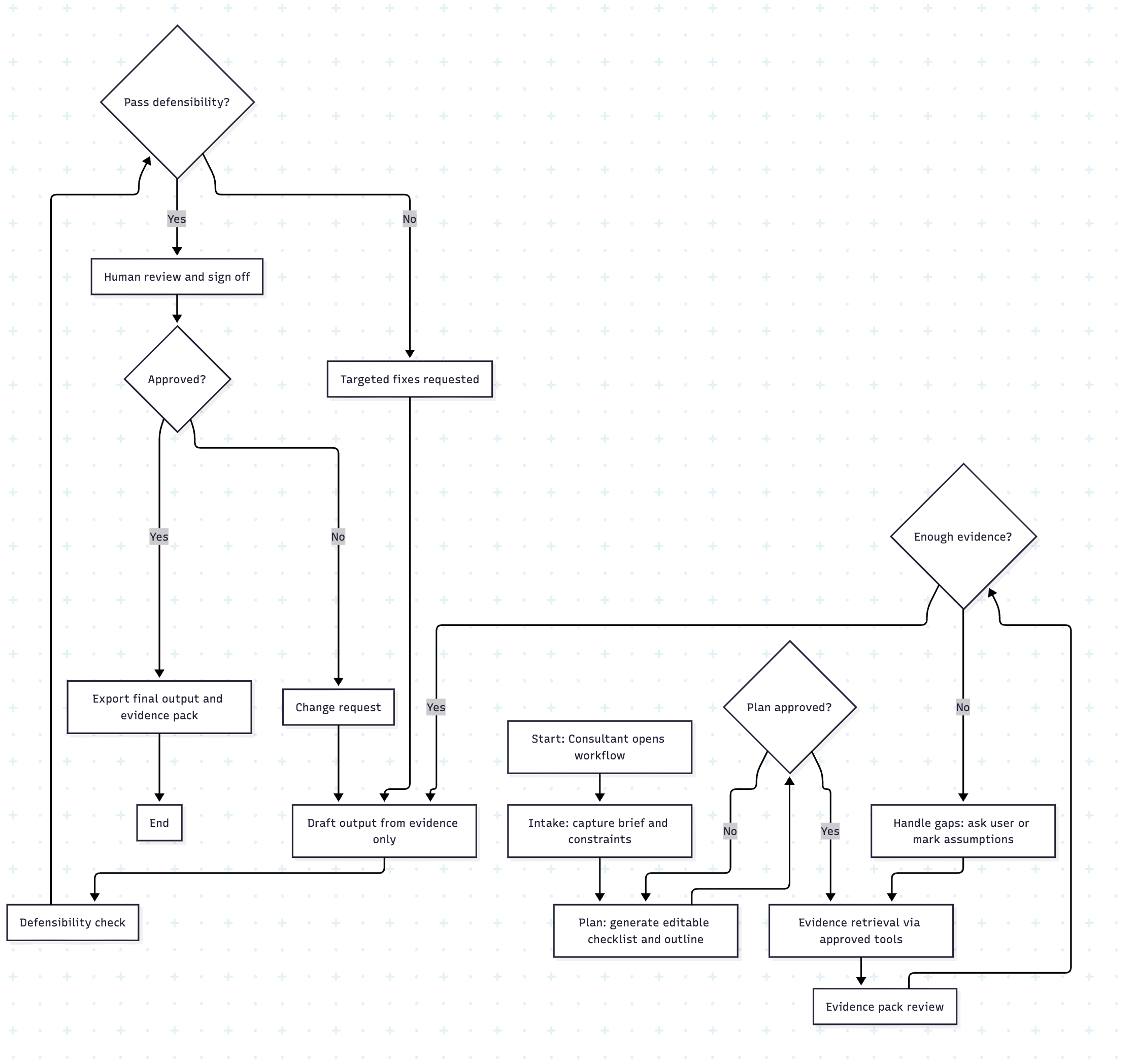
The MVP flow is deliberately simple and evidence-first:
Intake → Plan → Evidence Pack → Draft → Defensibility Check → Human sign-off → Export (draft + evidence pack + audit trail)


